今天由于要讲的废话非常非常的多,所以估计又来不及写算法了
之前关于买房这个话题的分析中,用到的大多是来源于中介张贴的房源信息,这个部分虽然足够让我们解决买房问题中的第一步,判断自己买得起哪些房子,但是当进入第二部分时,这些信息就远远不够了,因为第二个问题,是个比较主观性的问题,那就是我们对这些房源的满意程度是不是足以支撑起买房的意愿
之前的数据源:
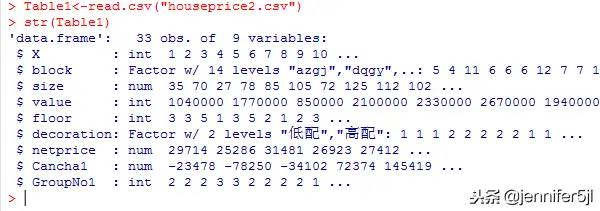
从这里,咱们开始需要大大地展开一个隐藏信息,小区名称(block)
所谓对房子的评估,有这么句很有道理的话,考虑房子最重要的三件事,就是地段、地段、还有地段
所以,别小看一个小区的名字,它至少可以体现一个非常关键的信息,地理位置
但是,地理位置这个东西的好坏其实是个非常个人化、非常主观、还叠加了非常多额外内容的信息,为什么呢?因为,我们着力于找一个好的地方,一方面要看它本身附近多繁荣、多便利,交通出行是否通畅;另一方面也要考虑一些更加个性化的需求,比如离爸妈家近不近,家里有学龄前的娃的话,要考虑一个比较好的学校有多远,家里有上了年纪的老人难免还要想想离医院远不远
而这一切,基本上都可以用一种量化的数据来体现距离
虽然从数学方法上来讲,我大可以把什么曼哈顿距离、欧式距离甚至闵可夫斯基距离再啰嗦一遍,这样今天的篇幅就肯定可以填完了,但是,抱着没有实际意义的数据就不是好数据的中心思想,我还是老老实实地用百度地图搜了所有已有的小区名称到各个不同重要地点的导航距离(远的用自驾车距离,近的用步行),得到了以下数据表

其中首列是小区名称,行标题是到哪个地点(依次为到交通站点、工作地点、医院、超市、父母家、学校),数值单位为公里数km
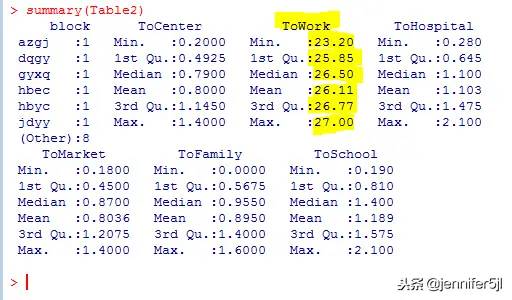
简单做个summary,可以看到我使用的房源数据其实属于是个不太恰当的极限通勤的例子虽然上下班方便真的重要,但我想都不用想也知道自己买不起离公司近的房子,因此,当弃疗时就弃疗
可是,光是评估一个地理位置的好坏就冒出来这么多列数据,咱不可能把它全部都扔进后续的计算,因为重复性的指标出现太多会明显影响地理位置在整个考虑过程中的占比,但这里已经找到的数据,出于人的感性认知来讲,又偏偏哪个都有点割舍不下的意味,怎么办呢?要不,咱想辙先合并一下?
你看,扯了这么一整篇的长度我才刚刚绕回正题上,咱的下一个计算任务,是把各小区到各重要地点的距离信息聚合到一起,把n列数据合并到一列:
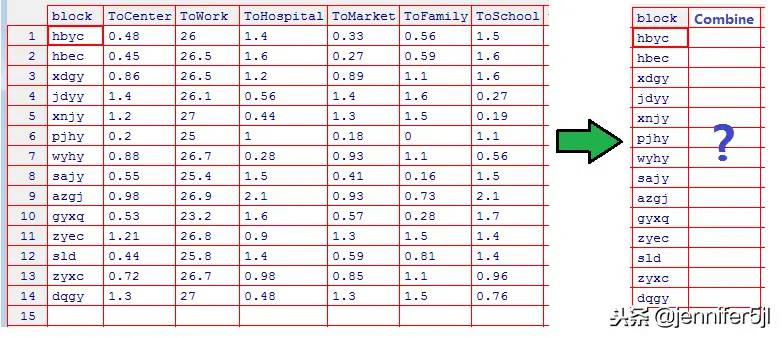
所以,下一篇的重点是降维
呜呜呜,这个貌似好难的说,感觉给自己出了个很坑的题目~~~~



















